
La Guía Definitiva para Extraer, Limpiar y Enriquecer Datos de Sales Navigator
La Guía Definitiva para Extraer, Limpiar y Enriquecer Datos de Sales Navigator
En este artículo, vamos a cubrir cómo extraer y enriquecer datos de LinkedIn Sales Navigator. Específicamente abordaremos los siguientes puntos:
-
El mejor software para extraer datos de LinkedIn.
-
Cómo crear búsquedas booleanas para encontrar personas en tu mercado
-
Organización sistemática de búsquedas y la creación de un diario de scraping
-
Principios básicos de limpieza de datos y filtrado de títulos de trabajo incorrectos
-
La plantilla exacta para enriquecer los datos de LinkedIn con campos faltantes como correos electrónicos y sitios web en Clay
Software de Scraping
La selección del software de scraping adecuado es la clave para obtener excelentes resultados. En nuestra experiencia, después de probar múltiples soluciones, hemos encontrado que Vayne.io es la mejor opción. Utilizamos Vayne.io principalmente porque la calidad es muy buena, ya que siempre y cuando intentes extraer una búsqueda de máximo 4500 personas, va a scrapear el 100% de resultados, a diferencia de otras herramientas que solo scrapean el 50-60% de los resultados de tu búsqueda de Sales Navigator.
Además, Vayne.io solo te cobra 79 USD mensuales por extraer 50,000 resultados. Una ventaja adicional es que el porcentaje de valores faltantes en columnas como sitios web, tamaño de empresa y otros campos es menor en comparación con otras herramientas que hemos probado.
En este link puedes acceder a Vayne: https://vayne.io/

Figura 1: Vayne.io, software de scraping
Arquitectura de Búsqueda Booleana
El primer paso y el más importante al intentar extraer datos de LinkedIn es construir correctamente tu búsqueda. Una búsqueda bien estructurada puede significar la diferencia entre capturar el 50% o el 100% de tu TAM.
Dentro de LinkedIn existen muchas formas de buscar personas, ya sea usando filtros de función o seniority, pero hemos encontrado que la mejor forma de acceder a todo tu TAM es mediante búsquedas booleanas.
Para poder construir una buena búsqueda booleana es importante conocer la estructura tradicional de los títulos de trabajo. Cada título de trabajo está formado por dos partes: el seniority level y las palabras clave relacionadas con el departamento o función del tomador de decisión.
Con el seniority level nos referimos específicamente a la palabra dentro del título de trabajo que hace alusión al nivel de autoridad de la persona. Por ejemplo: Gerente, Encargado, Director, etc.
Y con las palabras clave hacemos referencia a aquellos términos dentro del título de trabajo que nos indican a qué departamento pertenece una persona y cuál es su función. Por ejemplo: IT, HR, Marketing, etc.
A continuación puedes ver una tabla con distintos ejemplos de títulos de trabajo donde realizamos un desglose del seniority y las palabras clave para una mejor comprensión.
|
Título de Trabajo |
Seniority Level |
Palabras Clave (Departamento/Función) |
|
Gerente de TI |
Gerente |
TI |
|
Marketing Manager |
Manager |
Marketing |
|
Head of Sales |
Head |
Sales |
|
Encargado de Desarrollo de Software |
Encargado |
Desarrollo de Software |
|
Director de Recursos Humanos |
Director |
Recursos Humanos |
Figura 2: Estructura de títulos de trabajo
De acuerdo a esto cada búsqueda booleana tiene la siguiente estructura:

Figura 3: Estructura de búsqueda booleana
Cuando haces búsquedas booleanas en español tienes que tomar en cuenta que en LATAM muchas personas tienen en sus títulos de trabajo mezclas de palabras en inglés y en español. Por ejemplo, alguien puede tener Manager de Ventas o Head de Finanzas.
Por lo tanto, tu búsqueda booleana debe reflejar esto.
Entonces empecemos, ¿cómo se construye la búsqueda?
Primero para los seniority levels, no tienes que pensar, a continuación te comparto una búsqueda de todos los posibles seniority levels que vas a encontrar en títulos de trabajo de personas en LATAM.
Seniority levels: (Director OR Directora OR Jefa OR Jefe OR Supervisor OR Supervisora OR Coordinador OR Coordinadora OR Líder OR Leader OR Gerente OR Encargado OR Encargada OR Responsable OR Subdirector OR Subgerente OR Superintendente OR Head OR Manager OR VP OR Lead)
Por otro lado, las keywords son individuales para cada persona y se deben analizar cuidadosamente todas las posibles palabras que alguien dentro del departamento objetivo puede tener en su título en inglés y en español. Por ejemplo, si vendes desarrollo de software, las palabras clave pueden incluir IT, DevOps, Desarrollo de Software, Information Technology, entre otras. O si vendes marketing, podrían ser Marketing, Mercadeo, Mercadotecnia, entre otras.
Una vez que tienes las keywords completas tienes que construir la búsqueda booleana. A continuación te doy un ejemplo de una búsqueda booleana que construí para recursos humanos.
(Director OR Directora OR Jefa OR Jefe OR Supervisor OR Supervisora OR Coordinador OR Coordinadora OR Líder OR Leader OR Gerente OR Encargado OR Encargada OR Responsable OR Subdirector OR Subgerente OR Superintendente OR Head OR Manager OR VP OR Lead OR Gerencia OR Subgerente) AND ("Recursos humanos" OR HR OR "Human Resources" OR People OR RH OR Talento OR RRHH)
Metodología de Scraping Sistemática
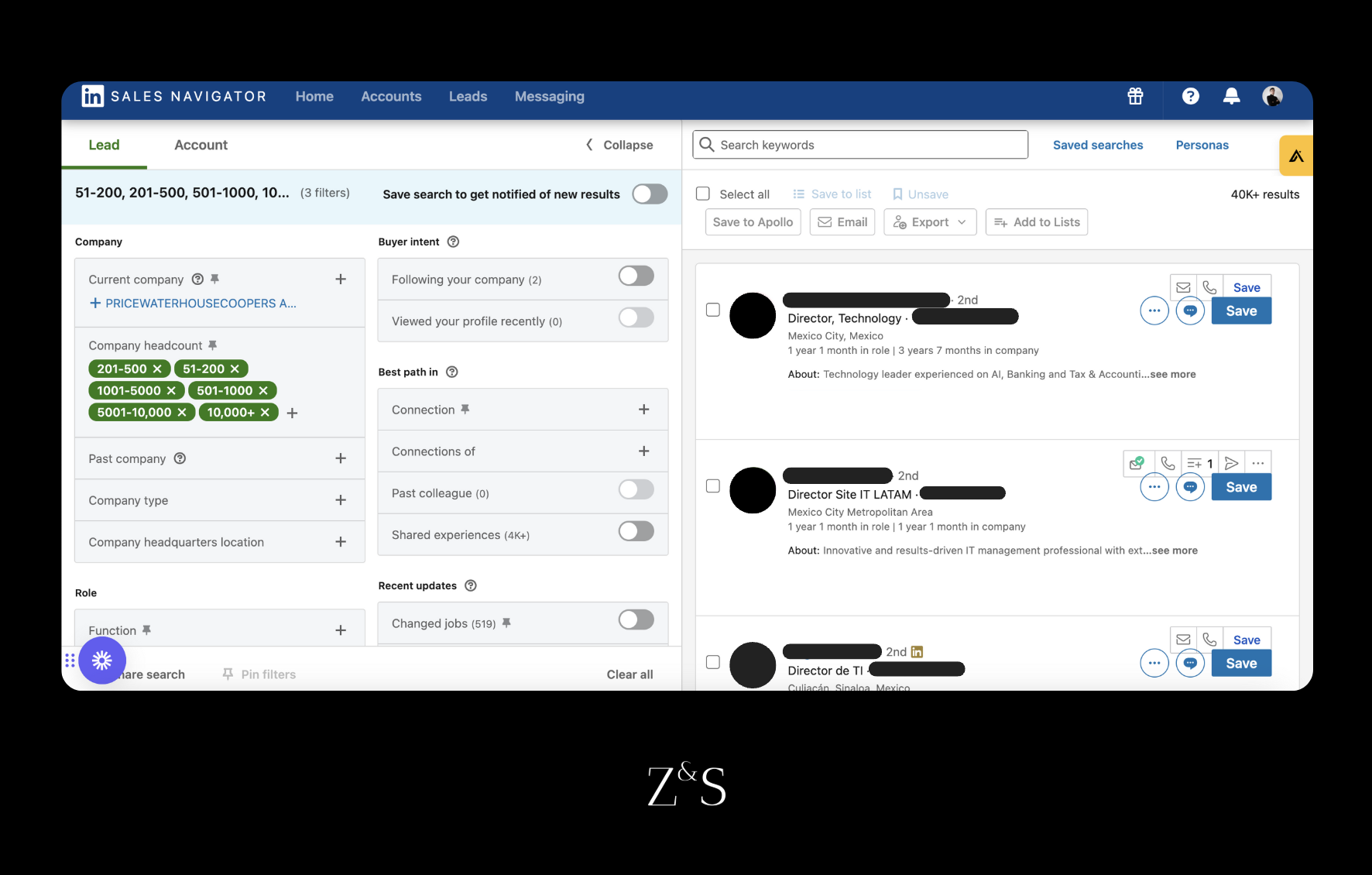
Una vez que tienes construida tu búsqueda booleana llega el momento de scrapear la búsqueda pero probablemente te vas a enfrentar a un problema: es probable que tu búsqueda sea de unas 10,000 o 20,000 personas.
Tan solo mira el ejemplo de a continuación donde construimos una búsqueda para un cliente que vende servicios tecnológicos. Acabamos con una búsqueda de 45,000 personas.
¿Qué es un diario de scraping?
Un diario de scraping es un documento en donde vamos a organizar todas nuestros badges de búsquedas y mantener un registro de todas las búsquedas que hemos extraido de Linkedin.
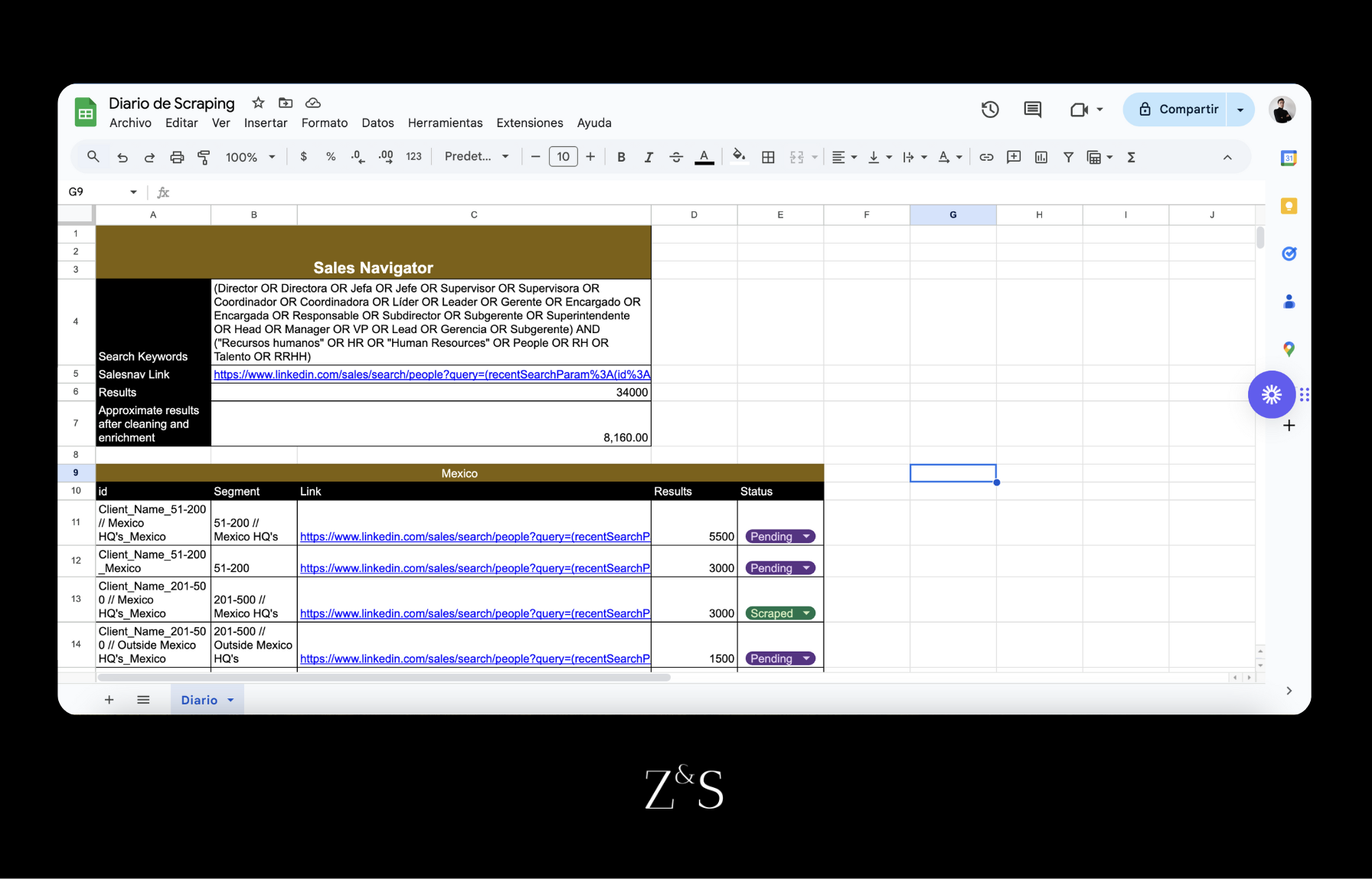
- ID: es un identificador que combina el nombre de la empresa con el segmento de búsqueda y región que se desea extraer. El propósito de este ID es poder identificar las búsquedas dentro de Vayne.io.
- Segmento: es una descripción del segmento de la búsqueda total que estamos extrayendo. Generalmente podemos crear segmentos con distintas combinaciones de las siguientes variables: región, tamaño de empresa y la ubicación de las oficinas centrales de las compañías.
- Link: es la URL de la búsqueda dentro de Sales Navigator
- Resultados: es el número total de personas en la búsqueda
- Status: nos permite identificar si ya hemos extraído esa búsqueda. Existen 3 estados: Scraped, Pending o Scraping.
¿Cómo hacer el breakdown de búsquedas?
Para realizar el breakdown de una búsqueda extensa, es necesario segmentarla utilizando los filtros disponibles en Sales Navigator. Los principales filtros que podemos usar son:
-
País de las personas
-
Ubicación de HQ's (Por ejemplo si haces una búsqueda en México empresas con HQ's en México y empresas con HQ's fuera de México)
-
Tamaño de empresa (1-10, 11-50, 51-200, 201-500, 501-1000, 1001-5000, 5001-10000, 10000+)
Por ejemplo, si tenemos una búsqueda de 20,000 personas, podríamos:
-
Primero dividirla por país
-
Si aún los segmentos son mayores a 4,500, subdividir por tamaño de empresa
-
Si es necesario, hacer una tercera división en base a la ubicación de los HQs
El objetivo es crear segmentos que no excedan los 4,500 resultados para garantizar una extracción completa de los datos.
En el siguiente link podrás ver un ejemplo de un diario de scraping donde realizamos el breakdown de una búsqueda de recursos humanos en México, dividiendo primero por número de empleados y luego por ubicación de HQ's hasta obtener segmentos de aproximadamente 4,500 personas.
Una vez construidas las búsquedas debes ir a Vayne.io y extraer una por una, teniendo en cuenta que Vayne.io tiene un límite de 15,000 resultados extraídos por cuenta. Conforme extraigas los resultados, actualiza el diario de scraping.
Protocolo de Limpieza de Datos
Después de descargar los datos de Vayne.io, el siguiente paso es limpiarlos. Primero debes eliminar las columnas innecesarias y renombrar las columnas, luego tienes que eliminar todas las empresas que no estén dentro del tamaño de empresa que elegiste así como la industria y finalmente limpiar los títulos de trabajo que no pertenezcan a tu público objetivo. Las primeras tareas son fáciles y se pueden hacer manualmente, pero la limpieza de títulos de trabajo es lo más complejo.
Limpieza de Títulos de trabajo
Cuando se trata de búsquedas en Sales Navigator, hemos encontrado que por más meticuloso que seas y agregues filtros, solo el 20-40% de tu búsqueda serán personas con el título de trabajo que elegiste en tus filtros. El resto pueden ser personas que no tienen relación alguna. Por ejemplo, puedes hacer una búsqueda de tomadores de decisión de IT y que aparezca alguien con el título de "CFO" u otros títulos no relacionados. Por lo tanto, siempre que realizas una búsqueda en Sales Navigator, estás obligado a filtrar tu dataset para eliminar todos los títulos de trabajo incorrectos.
Muchas personas suelen filtrar los títulos de trabajo en Google Sheets analizando uno por uno y eliminando aquellos que no pertenecen a su público objetivo. Otros profesionales utilizan condiciones para clasificar a los contactos por sus niveles de experiencia. Por ejemplo, pueden solicitar a ChatGPT que genere una nueva columna denominada "Seniority Level" y asigne a cada persona una categoría como "Gerente", "Manager" o "C-Suite". De esta manera, en lugar de filtrar los títulos de trabajo individualmente, pueden clasificarlos directamente por seniority levels.
El problema con ambos métodos es que son demasiado tardados y además son propensos a errores, ya que cuando se necesita revisar listas de títulos de trabajo de 1,000 personas en un solo grupo, es inevitable cometer errores.
Debido a esto, necesitamos una solución que nos permita filtrar las bases de datos de manera más eficiente, y esta solución es el Clustering. El Clustering consiste en agrupar datos basados en sus similitudes, creando grupos o "clusters" de elementos que comparten características comunes. Por ejemplo, si en la base de datos tenemos muchos títulos de trabajo diferentes como "IT Director", "DevOps Manager" y "Analista de Sistemas", se haría un cluster con todos los directores de IT, otro cluster con todos los managers de DevOps y otro con todos los analistas de sistemas y de esta forma es más fácil filtrar la base de datos porque simplemente vas cluster por cluster para eliminar los títulos de trabajo incorrectos.
Existen diversos algoritmos de clustering pero el más efectivo para bases de datos B2B es HDBSCAN. En este artículo no explicaremos a profundidad cómo funciona debido a que ya hemos abordado este tema anteriormente. En el siguiente artículo puedes encontrar una explicación a profundidad sobre cómo filtrar datasets de Sales Navigator: https://insights.zsbusinessconsulting.com/article/harnessing-hdbscan-a-quantum-leap-in-b2b-targeting
Enriquecimiento de Datos
Después de filtrar la base de datos y eliminar los títulos de trabajo incorrectos, el siguiente paso es enriquecer este dataset para encontrar los emails de los tomadores de decisión. Para esto contamos con un template en Clay que hemos utilizado para sistematizar este proceso.
En este link puedes acceder al template: https://app.clay.com/shared-table/share_ufHr2sEodjkA
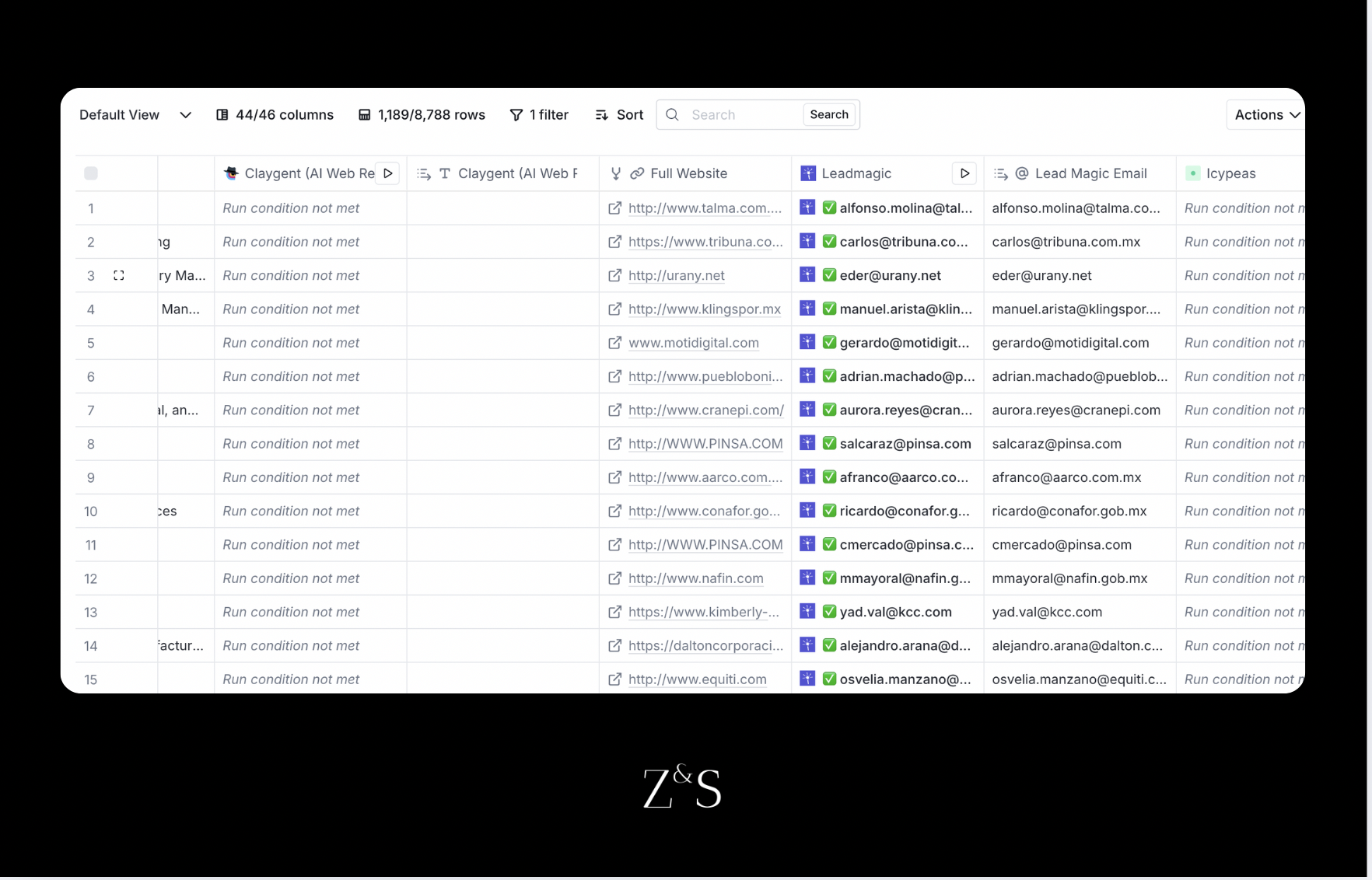
Figura 6: Template de Clay para Enriquecimiento de datos de Sales Navigator
Este template funciona en varios pasos. Primero, buscamos los sitios web faltantes del dataset usando claygent. Luego, realizamos un merge entre la columna de sitios web de claygent y la columna original para crear una master column. Con esta información, procedemos a la búsqueda de emails mediante waterfall enrichment, que consiste en buscar emails de manera escalonada en varios proveedores hasta encontrarlos. El proceso en Clay es simple y permite lograr un enrichment del 50-80% de las búsquedas de Sales Navigator. Finalmente, validamos los emails usando Million Verifier y Catch-all Verifier.
A través de este proceso sistemático se logra pasar de una búsqueda en LinkedIn Sales Navigator hasta obtener una base de datos limpia con emails verificados de tomadores de decisión.
