
HDBSCAN: El Método Más Efectivo para Limpiar Datos de Sales Navigator para la Generación de Leads B2B
HDBSCAN: El Método Más Efectivo para Limpiar Datos de Sales Navigator para la Generación de Leads B2B
Introducción
En el mundo de la generación de leads B2B, LinkedIn Sales Navigator se destaca como una de las mejores fuentes de datos para obtener información de tomadores de decisiones. No es un secreto que la mayoría de las bases de datos B2B, ya sea que lo admitan o no, obtienen sus datos directamente de Sales Navigator, ya que es la fuente de datos B2B más grande y actualizada que existe.
Debido a esto, en nuestra agencia decidimos que, para no depender de ninguna base de datos B2B en particular, como Apollo, teníamos que hacer la misma labor que ellos y obtener nosotros nuestros propios datos. La ventaja de obtener datos directamente de LinkedIn es que siempre vas a contar con la información más actualizada, además de que vas a tener una mayor cantidad de datos que en las bases de datos. Por ejemplo, puede que en una base de datos tu búsqueda sea de 10,000 personas, pero si vas a LinkedIn y haces la misma búsqueda, puedes encontrar 50,000.
Cuando scrapeamos LinkedIn Sales Navigator, nos enfocamos particularmente en extraer el nombre y apellido de las personas, su empresa y sitio web, para luego poder aplicar una estrategia que llamamos "Waterfall Enrichment", la cual consiste en poner estos data points en varias plataformas que tienen algoritmos para encontrar emails. Básicamente, hacemos API calls a varias plataformas a la vez para poder tener un mayor match rate. Por ejemplo, primero buscamos el correo en Icypeas, y si no lo encuentra, vamos a Findymail, y así sucesivamente.
El gran problema con LinkedIn Sales Navigator es que, a pesar de los filtros avanzados que ofrece, las búsquedas no son muy precisas. Por más que realices búsquedas booleanas y ajustes las condiciones, encontrarás que los resultados solo tienen entre un 20% y 40% de precisión. Por ejemplo, al buscar CFOs, es posible que aparezcan títulos completamente irrelevantes, como "profesor" u otros roles que no tienen relación con finanzas. Esto significa que, si obtienes datos de Sales Navigator, vas a tener que pasar un buen tiempo limpiando el dataset de personas para asegurarte de que solo queden aquellas que originalmente pusiste en tu búsqueda.
Desafíos para Filtrar Títulos de Trabajo de Sales Navigator
Dado que necesitamos scrapear una gran cantidad de datos en LinkedIn Sales Navigator, era esencial desarrollar una metodología eficiente para limpiar estas bases de datos sin tener que recurrir a un exceso de trabajo manual.
Es común que muchas personas intenten filtrar estas bases de datos utilizando niveles de seniority. Por ejemplo, aplicando filtros en Excel para enfocarse primero en los managers, luego en los directores, después en los supervisores, y así sucesivamente. El problema con este enfoque es que muchos niveles de seniority contienen diversas palabras clave que no están necesariamente relacionadas entre sí. Además, cuando se trabaja con bases de datos grandes, este método se vuelve impráctico, ya que cada nivel de seniority incluye demasiados elementos, lo que hace que la lista sea interminable.
Por ejemplo, si tienes una base de datos de 5,000 personas y solo consideras 5 niveles de seniority, tendrás que revisar manualmente 5 grupos de 1,000 elementos, lo cual resulta muy laborioso. La solución más efectiva es dividir todo el dataset en clusters más pequeños y manejables.
Para lograr esto, utilizamos un algoritmo de clustering llamado K-Means, muy popular en el campo de la ciencia de datos. Este algoritmo nos ayudó a identificar patrones dentro de los datos y a crear grupos de títulos de trabajo similares entre sí. Primero extraíamos los datos de Sales Navigator y luego aplicábamos K-Means para formar estos grupos, lo que nos permitía filtrar la información de manera mucho más eficiente.
Las Limitaciones de K-Means
El problema que encontramos al aplicar K-Means es que, aunque funcionaba muy bien con los datos de Apollo, ya que estos datos están más estructurados y hacía sentido utilizar este algoritmo, notamos que no era igual de adecuado para los datos de Sales Navigator. K-Means realiza varias suposiciones que nos generaron inconvenientes.
En primer lugar, K-Means requiere que se defina un número de clústeres antes de iniciar el proceso, lo que significa que debes tener una idea previa de cuántos grupos se van a formar. Esto no es práctico en Sales Navigator, donde es imposible saber de antemano cuántos clústeres surgirán, debido a la gran cantidad de datos irrelevantes y la diversidad de títulos de trabajo que se encuentran en una misma búsqueda. Por lo tanto, no se puede determinar el número ideal de clústeres de manera precisa.
El segundo problema es que K-Means asume que todos los clústeres tienen un tamaño uniforme y una forma esférica, algo que rara vez ocurre con los datos de Sales Navigator. Esta suposición puede ocasionar resultados imprecisos.
El tercer inconveniente es la sensibilidad al ruido. K-Means tiene dificultades para identificar outliers o puntos que realmente no pertenecen a ningún clúster. En una búsqueda de Sales Navigator, es común que haya datos que simplemente sean ruido y no deban agruparse. Sin embargo, al usar K-Means, estos puntos terminan asignados a un clúster debido a que el número de grupos ya fue predefinido.
Por lo tanto, aunque K-Means era muy efectivo con Apollo, descubrimos que los resultados en Sales Navigator no eran muy buenos.
El Descubrimiento: HDBSCAN y Técnicas Avanzadas de Ciencia de Datos
Durante una tarde en la que estábamos filtrando datos de Sales Navigator, nos dimos cuenta de que necesitábamos encontrar una manera diferente para realizar el clustering, ya que era muy frustrante tener que lidiar con clústeres mal formados y filtrar los datos de esa manera. Entonces nos preguntamos: ¿qué tal si existiera un método mucho más avanzado que pudiera resolver este problema? Nos pusimos a investigar y encontramos un artículo llamado Density-Based Clustering Based on Hierarchical Density Estimates de Campello, Moulavi y Sander. Este artículo introducía la idea de HDBSCAN, un algoritmo de clustering mucho más avanzado que iba a transformar la forma en la que filtramos bases de datos B2B.
Nuestro camino con HDBSCAN comenzó como un simple experimento, pero rápidamente se convirtió en una parte fundamental de nuestra metodología para filtrar datos B2B. Este algoritmo ofrecía soluciones a muchos de los problemas que habíamos enfrentado con K-Means:
-
Detección Dinámica de Clústeres: HDBSCAN determina automáticamente el número óptimo de clústeres de acuerdo a la estructura inherente de los datos, eliminando la necesidad de suposiciones previas.
-
Clustering Basado en Densidad: HDBSCAN realiza un clustering basado en la densidad, enfocándose en áreas donde hay una alta concentración de puntos y permitiendo la identificación de clústeres de diferentes formas y tamaños, reflejando las agrupaciones naturales presentes en el dataset de títulos de trabajo.
-
Manejo de ruido: El algoritmo identifica y aísla eficazmente los puntos atípicos, asegurando que estos no distorsionen nuestro análisis.
Implementación Paso a Paso de HDBSCAN
1. Preparación y Limpieza de Datos
El dataset que utilizamos para este artículo fue scrapeado de LinkedIn Sales Navigator utilizando Vayne.io, enfocándonos exclusivamente en tomadores de decisión del departamento de finanzas. Este dataset cuenta con 5,119 títulos de trabajo.
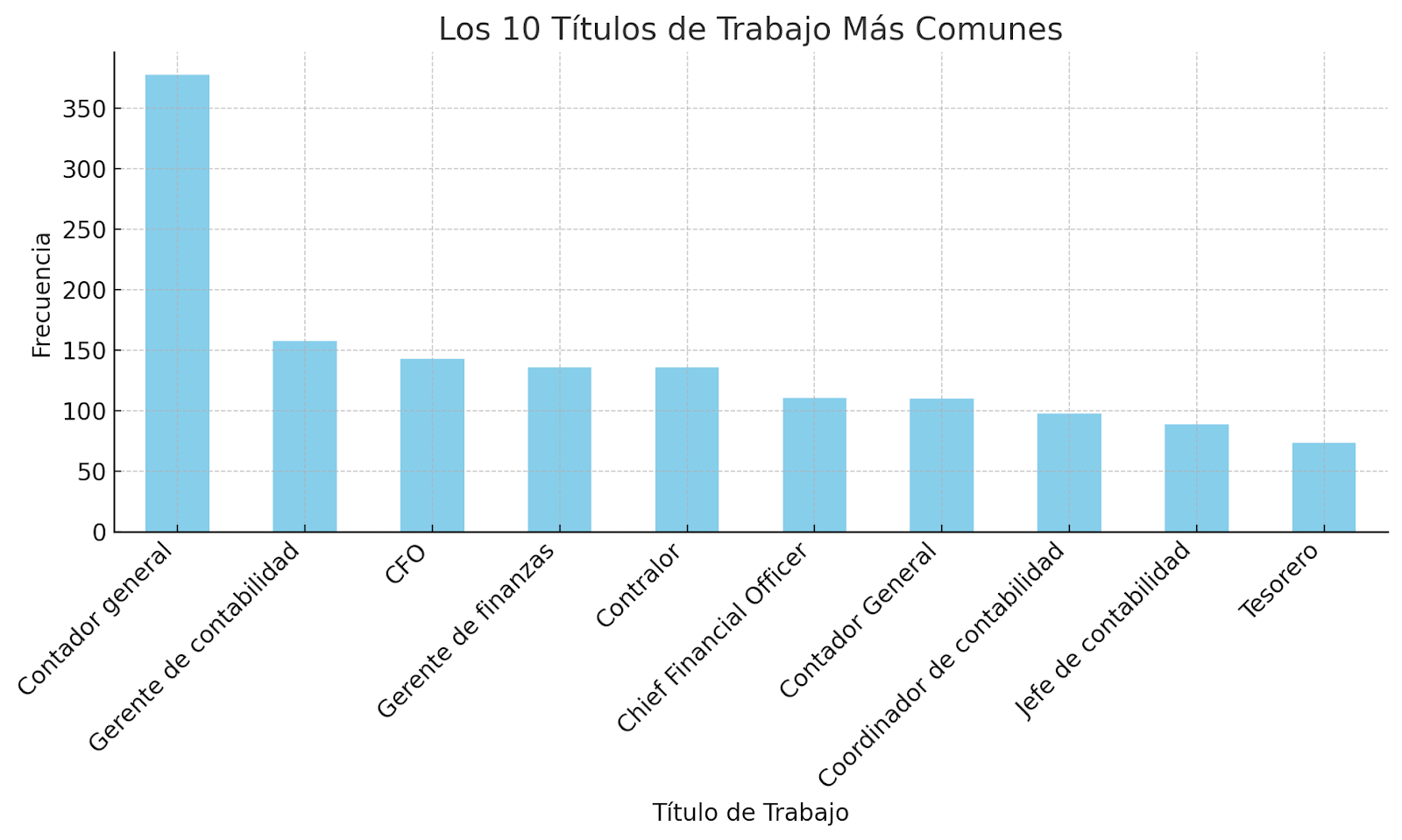
Para proporcionar contexto, realizamos un análisis inicial de los títulos de trabajo dentro del dataset. A continuación, se muestra una gráfica con los 10 títulos de trabajo más comunes en el dataset
Antes de aplicar técnicas avanzadas de clustering, preparamos y limpiamos el dataset para asegurar una base sólida en el análisis y su posterior agrupación con HDBSCAN.
Específicamente:
• Importamos el dataset como un CSV
• Eliminamos columnas innecesarias que contienen datos irrelvantes.
• Renombramos columnas para asegurar consistencia.
• Reformateamos los datos de la ubicación, extrayendo solo el nombre del país para estandarizar la entrada.
Código de esta sección
2. BERT Embeddings Generation
En este paso, convertimos los títulos de trabajo en embeddings utilizando BERT (Bidirectional Encoder Representations from Transformers). Un embedding es una representación numérica de un texto que captura el significado de una palabra o frase en un vector denso de números reales. Estos vectores nos permiten cuantificar las relaciones y similitudes entre palabras o frases.
Por ejemplo, un título como "Gerente de Administración y Finanzas" puede convertirse a números. BERT originalmente convierte todo en un vector de 768 dimensiones, pero para simplificarlo, supongamos que lo reduce a solo tres dimensiones: entonces, el título "Gerente de Administración y Finanzas" podría representarse como [-0.42, 0.21, -0.15]. Cada número en este vector representa algún aspecto del significado del título, como su nivel de seniority, departamento o función. Los títulos similares tendrán valores similares y, por lo tanto, cuando los visualicemos, aparecerán más o menos en el mismo punto.
Para ofrecer un ejemplo más claro, a continuación se muestra una tabla con algunos títulos de trabajo junto con los primeros tres valores de sus respectivos vectores de embedding.
|
Título |
Embedding (primeros 3 valores) |
|
Gerente de Administración y Finanzas |
['-0.42', '0.21', '-0.15'] |
|
Gerente de Administración y Finanzas Automotriz |
['-0.42', '0.21', '-0.15'] |
|
Dirección Administración y Finanzas |
['-0.48', '0.10', '-0.32'] |
|
Accounting Director |
['-0.75', '0.17', '-0.42'] |
|
FINANCIAL PLANNING DIRECTOR |
['-0.57', '0.18', '-0.42'] |
Visualización de Embeddings de Títulos de Trabajo con UMAP
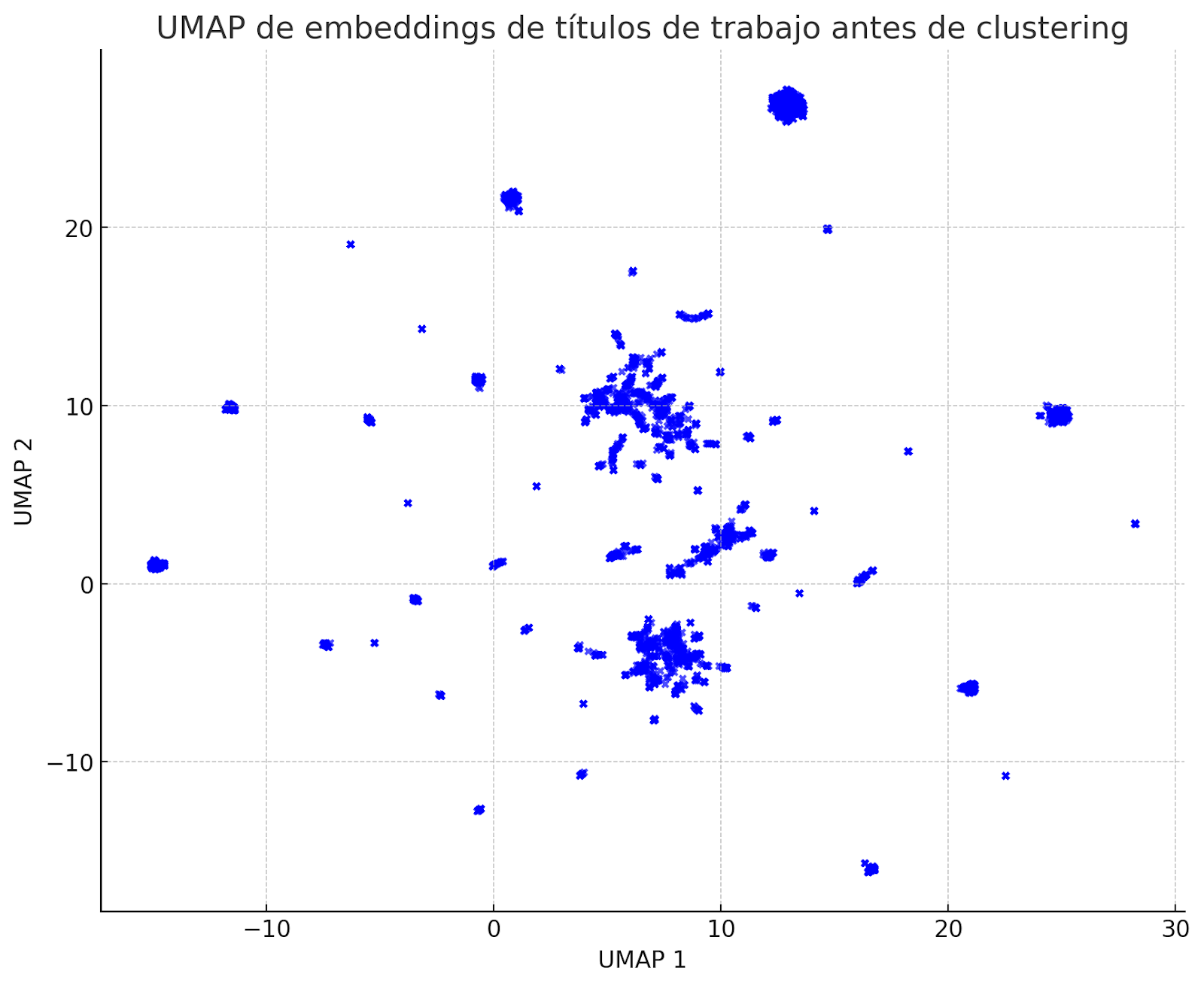
Para explorar más a fondo las relaciones entre los distintos títulos de trabajo, aplicamos UMAP (Uniform Manifold Approximation and Projection) para reducir los embeddings de BERT, de 768 dimensiones, a un espacio 2D. Esta reducción de dimensionalidad nos permite visualizar cómo se agrupan los distintos títulos de trabajo según sus similitudes semánticas.
UMAP es un algoritmo que proyecta datos de alta dimensionalidad a un espacio de menor dimensión, manteniendo las relaciones de proximidad y estructura del conjunto original. En otras palabras, UMAP preserva las distancias y similitudes entre los títulos de trabajo, incluso después de la reducción de dimensionalidad. Esto nos permite observar cómo se agrupan los datos, de modo que los títulos de trabajo que están más cerca entre sí en la gráfica tienen características o significados similares.
Al aplicar UMAP, los puntos densos tienden a agruparse, formando clusters de manera natural. Estos clústeres representan grupos de títulos de trabajo que comparten similitudes y que, más adelante, probablemente terminarán convirtiéndose en uno de nuestros clusters.
Código para generar embeddings
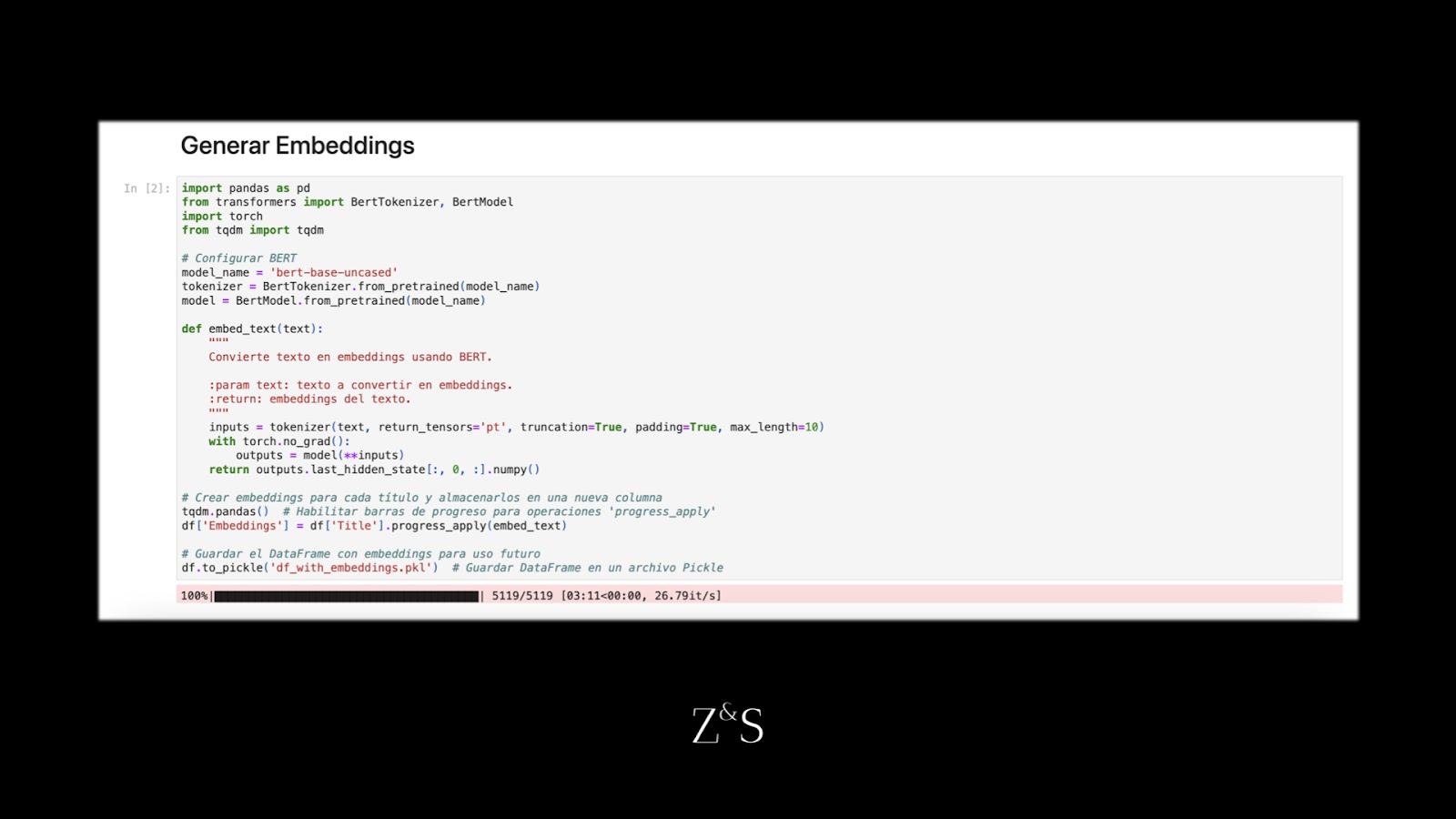
3. Reducción de dimensionalidad
Después de convertir los títulos de trabajo en embeddings de alta dimensionalidad, al igual que en el paso anterior debemos reducir la dimensionalidad de estos vectores pero no a dos dimensiones. Debido a que los embeddings generadors por BERT tienen 768 dimensiones puede causar problemas al hacer clustering. Los datos de alta dimensionalidad pueden volverse dispersos, lo que dificulta a los algoritmos de clustering identificar grupos significativos.
The Curse of Dimensionality
En machine learning, the “curse of dimensionality” se refiere al hecho de que, a medida que aumenta el número de dimensiones, los dato points se vuelven cada vez más dispersos. En espacios de alta dimensionalidad, cada punto se aleja más de los demás, lo que hace que sea difícil distinguir patrones significativos. Como resultado, los algoritmos de clustering tienen dificultades para identificar grupos bien definidos porque las métricas de distancia (como la distancia euclidiana) se vuelven menos fiables.
Para combatir esto, reducimos la dimensionalidad de nuestros embeddings para enfocarnos en las características más relevantes. Al condensar la información en menos dimensiones, podemos mantener la estructura central de los datos, eliminando el ruido y las características irrelevantes.
Usando el Conteo de palabras para determinar dimensiones
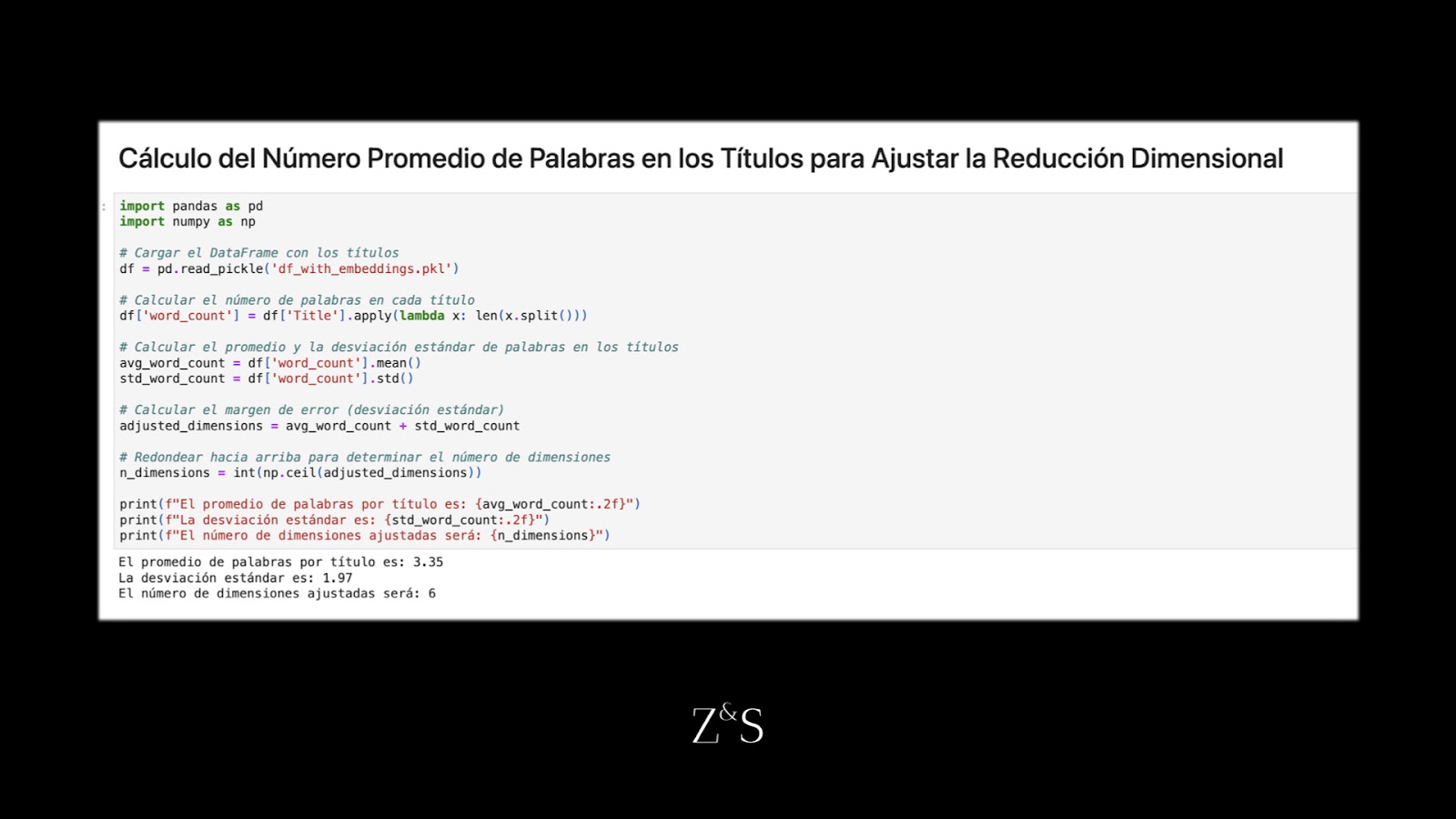
En nuestro caso, los títulos de trabajo suelen consistir en un pequeño número de palabras. Por lo tanto, es probable que la estructura de nuestros datos pueda capturarse con muchas menos de 768 dimensiones. Para determinar un número más óptimo de dimensiones, calculamos el promedio de palabras por título.
La lógica aquí es sencilla:
1. Recuento promedio de palabras Primero calculamos el número promedio de palabras por título. Esto nos da una estimación de cuántas dimensiones se necesitan para capturar la información contenida en un título promedio. Para comprender mejor la distribución del recuento de palabras en los títulos, presentamos el siguiente histograma:
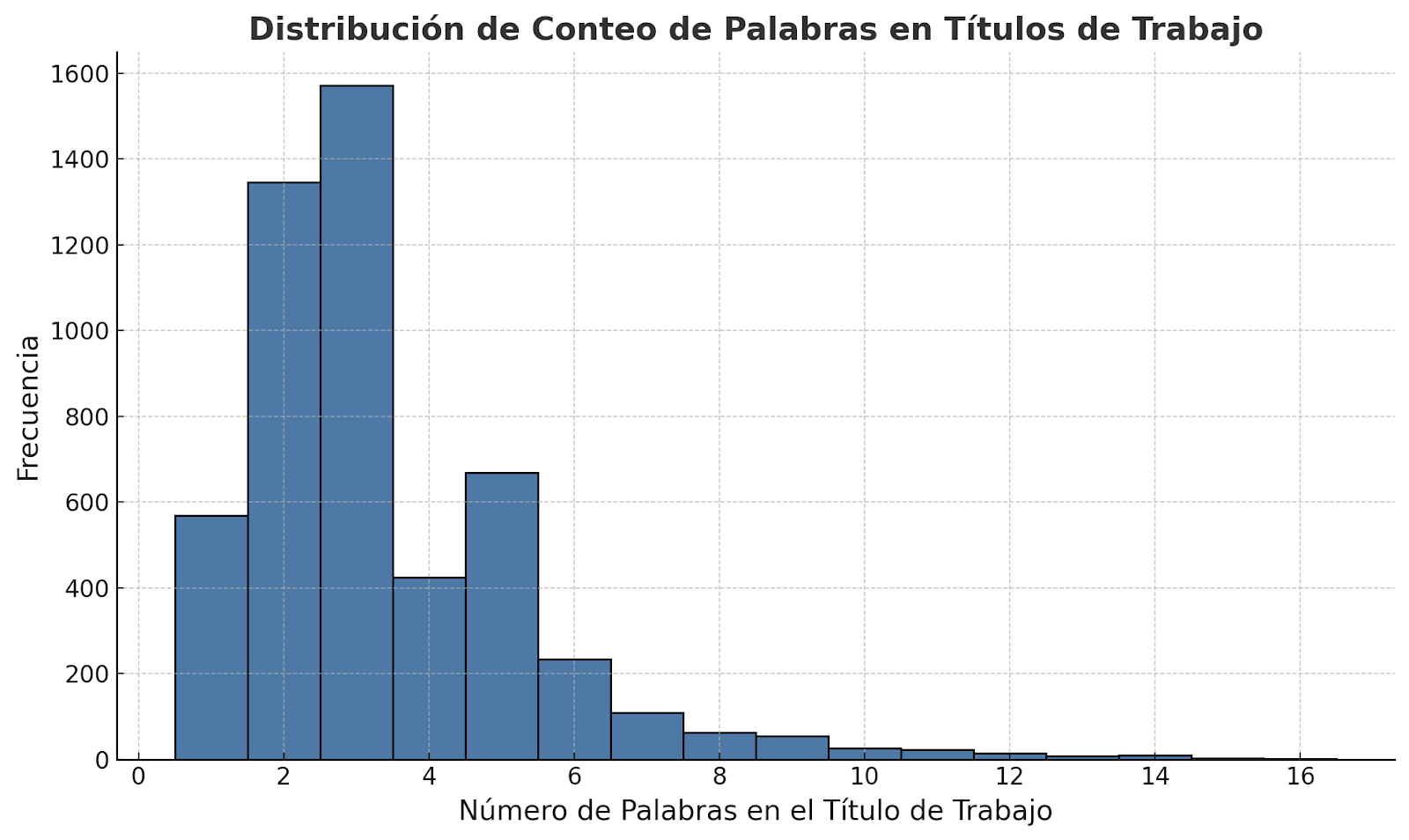
2. Desviación estándar como margen de error: Luego calculamos la desviación estándar, que representa la variación en el recuento de palabras en todo el conjunto de datos. Al añadir este margen de error, nos aseguramos de no perder información importante durante la reducción de dimensionalidad.
3. Redondeo: Finalmente, redondeamos la suma del recuento promedio de palabras y la desviación estándar al número entero más cercano. Esto garantiza que no estemos subestimando el número de dimensiones requeridas.
Matemáticamente, esto puede representarse como:
n_dimensions = ⌈ avg_word_count + std_word_count⌉
Donde:
- avg_word_count es el número promedio de palabras por título.
- std_word_count es la desviación estándar, que actúa como un margen de error.
El símbolo ⌈ ⌉ denota que estamos redondeando al número entero más cercano.
Este cálculo nos da un número de dimensiones ajustado y relevante en contexto, que se alinea con la estructura de nuestros datos.
En este caso específico, encontramos que los títulos de trabajo tienen en promedio entre 3 y 4 palabras, con cierta variación. Utilizando este enfoque, determinamos que reducir la dimensionalidad a alrededor de 5 o 6 dimensiones captura la estructura esencial de los títulos de trabajo mientras se evitan los problemas asociados con los espacios de alta dimensionalidad.
Código para calcular dimensiones
4. HDBSCAN Clustering
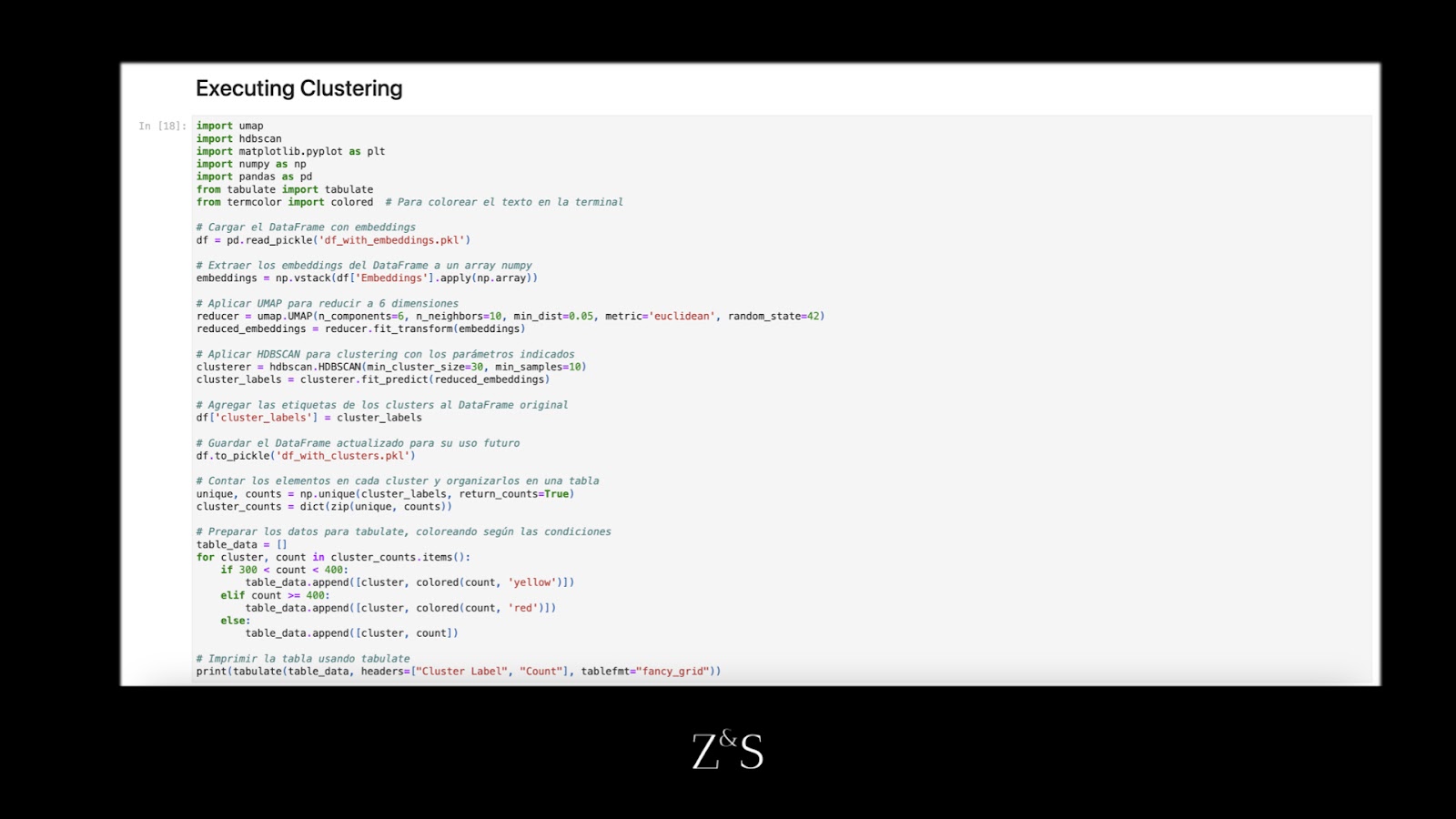
Una vez que hemos reducido la dimensionalidad de nuestros embeddings, el siguiente paso es aplicar HDBSCAN para realizar el clustering. A continuación, desglosamos los parámetros clave y cómo están configurados para este paso:
Parámetros de HDBSCAN:
-
min_cluster_size=30:
-
Qué hace: El parámetro min_cluster_size determina el número mínimo de puntos que un grupo debe tener para ser considerado un clúster válido. Este parámetro afecta directamente cuán detallados o amplios serán los clústeres.
-
Por qué lo elegimos: En la práctica, este valor suele determinarse mediante experimentación. Para nuestro caso, después de realizar varias iteraciones con diferentes conjuntos de datos, encontramos que un valor inicial de 30 funciona bien para los títulos de trabajo. Este valor ofrece un buen equilibrio entre crear clústeres que sean significativos sin ser demasiado granulares. Sin embargo, esto es solo un punto de partida, y dependiendo de la complejidad del dataset, este parámetro puede requerir ajustes adicionales. Optamos por 30 porque generalmente es un buen punto intermedio que resulta en clústeres lo suficientemente grandes para una revisión práctica, pero lo suficientemente pequeños como para ser útiles en el filtrado.
-
min_samples=10:
-
Qué hace: El parámetro min_samples afecta la densidad requerida para que los puntos sean considerados parte de un clúster. Establece el número mínimo de puntos que deben estar dentro de un vecindario para que ese punto sea considerado "central" en el clúster.
-
Por qué lo elegimos: Un valor bajo, como 10, nos permite capturar clusters que, aunque tienen una menor densidad, siguen siendor elevantes. Para el clustering de títulos de trabajo, donde los datos pueden ser algo ruidosos, establecer este parámetro demasiado alto podría hacer que agunos títulos relevantes sean etiquetados como ruido. Mediante nuestros experimentos determinamos que min_samples=10 nos permite mantener flexibilidad mientras seguimos capturando agrupaciones significativas.
-
UMAP Parameters - n_neighbors=10, n_components=6, and min_dist=0.05:
-
n_neighbors=10: Este parámetro controla el equilibrio entre la estructura local y global de los datos. Al configurarlo en 10, nos enfocamos más en capturar agrupaciones locales mientras mantenemos suficiente contexto global para evitar clústeres demasiado pequeños o fragmentados.
-
n_components=6: El número de dimensiones al que reducimos, basado en nuestro análisis del recuento promedio de palabras en los títulos de trabajo.
-
min_dist=0.05: Este parámetro controla cuán compactos son los puntos dentro de cada cluster. Un valor bajo como 0.05 asegura que los puntos dentro de un cluster permanezcan cercanos, promoviendo clusters más compactos y precisos. Esta configuración es particularmente útil para identificar pequeños clústeres bien definidos, lo cual es crítico cuando se trabaja con este tipo de datasets.
Marcando y Manjeando Clusters Grandes
Un desafío clave en nuestro workflow son los clústeres que son demasiado grandes, específicamente aquellos con más de 300 elementos. Los clústeres grandes a menudo contienen una mezcla de títulos que no están tan relacionados como deberían, lo que hace que la revisión manual sea tediosa. Descubrimos que es más práctico tener más clústeres con menos elementos, incluso si esto resulta en un mayor número de clústeres en general.
En nuestro código, marcamos los clusters con más de 300 elementos (amarillo para clústeres con 300-400 elementos y rojo para aquellos con 400 o más). Esto nos ayuda a identificar fácilmente que clusters necesitan refinarse.
En el filtrado de bases de datos B2B, los clusters grandes complican la eliminación de datos irrelevantes. Al dividir estos clusters en grupos más específicos y homogéneos, logramos filtrar leads de manera más rápida. Aunque este enfoque genera más clusters, reduce considerablemente el tiempo necesario para revisarlos manualmente. No obstante, si un cluster grande es homogéneo (por ejemplo, uno de 700 elementos con solo tres títulos de trabajo diferentes), no representa un problema y puede dejarse tal como está.
Código para ejecutar clustering HDBSCAN
Visualización y Análisis de Clusters
Una vez completado el clustering inicial, el siguiente paso crucial consiste en visualizar los clusters para identificar posibles problemas, particularmente con los clusters grandes o puntos de ruido que podrían reclasificarse. La visualización ayuda a obtener una imagen clara de qué tan bien ha funcionado el proceso de clustering y resaltar áreas que pueden refinarse.
En este paso, graficamos los clusters para evaluar su composición y revisamos manualmente los clusters más grandes. En el siguiente gráfico, mostramos los cinco clusters más comunes junto con sus títulos de trabajo correspondientes. Como se puede observar, los títulos que comparten significados semánticos similares, como "CFO" y "Contador General", se agrupan en clusters similares, lo que confirma que el algoritmo de clustering organizó los títulos de trabajo de manera correcta.
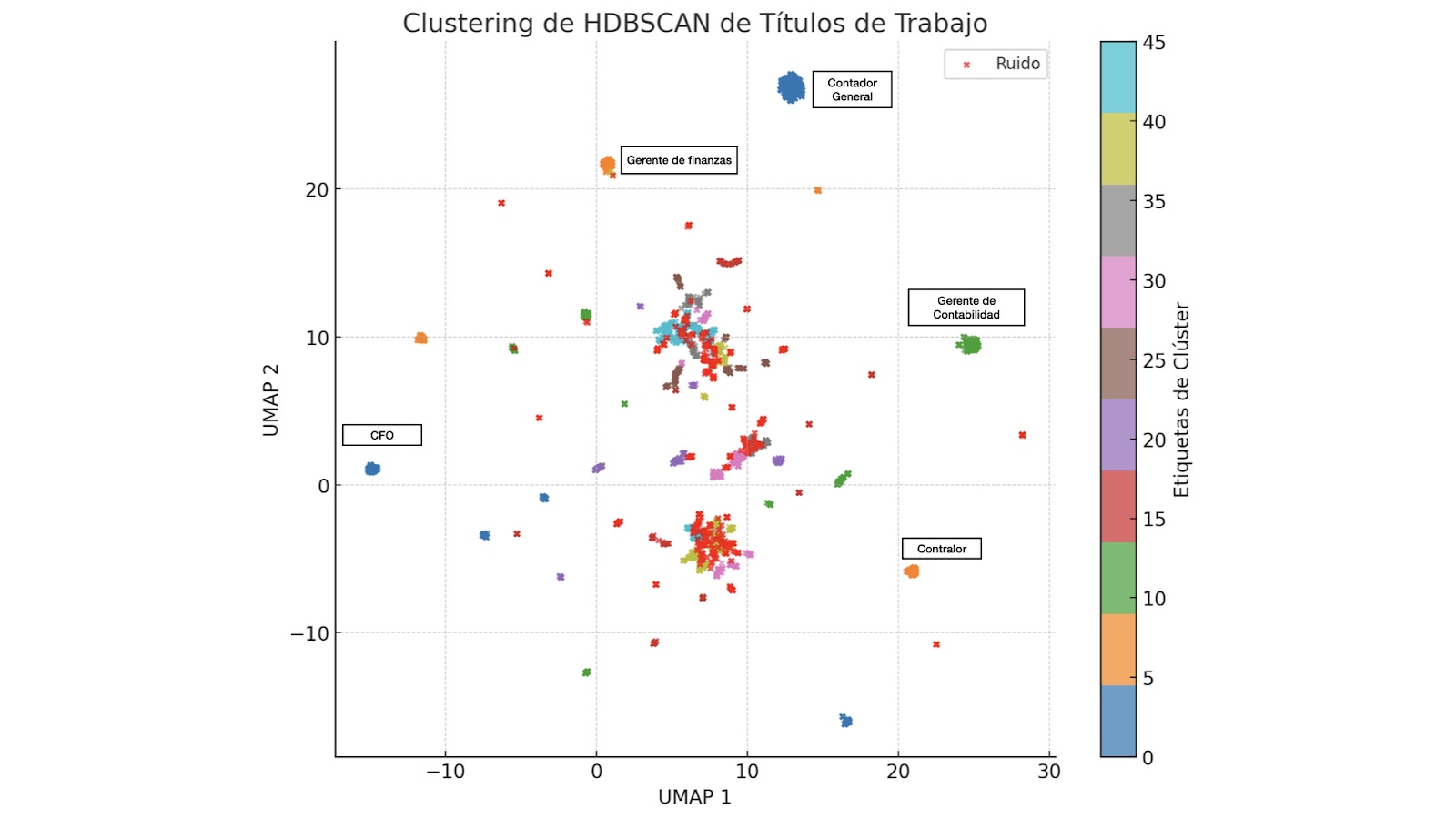
Generamos un gráfico de barras para visualizar el número de elementos en cada clúster y, al revisar los resultados, descubrimos que solo el ruido y el Clúster 4 tenían más de 300 elementos. Sin embargo, al examinar el Clúster 4, que contenía 587 elementos, nos dimos cuenta de que no representaba un problema, ya que todos los puntos correspondían al título "Contador General", lo que lo hacía un clúster altamente homogéneo. Como mencionamos anteriormente, los clústeres grandes solo son problemáticos si no son homogéneos.
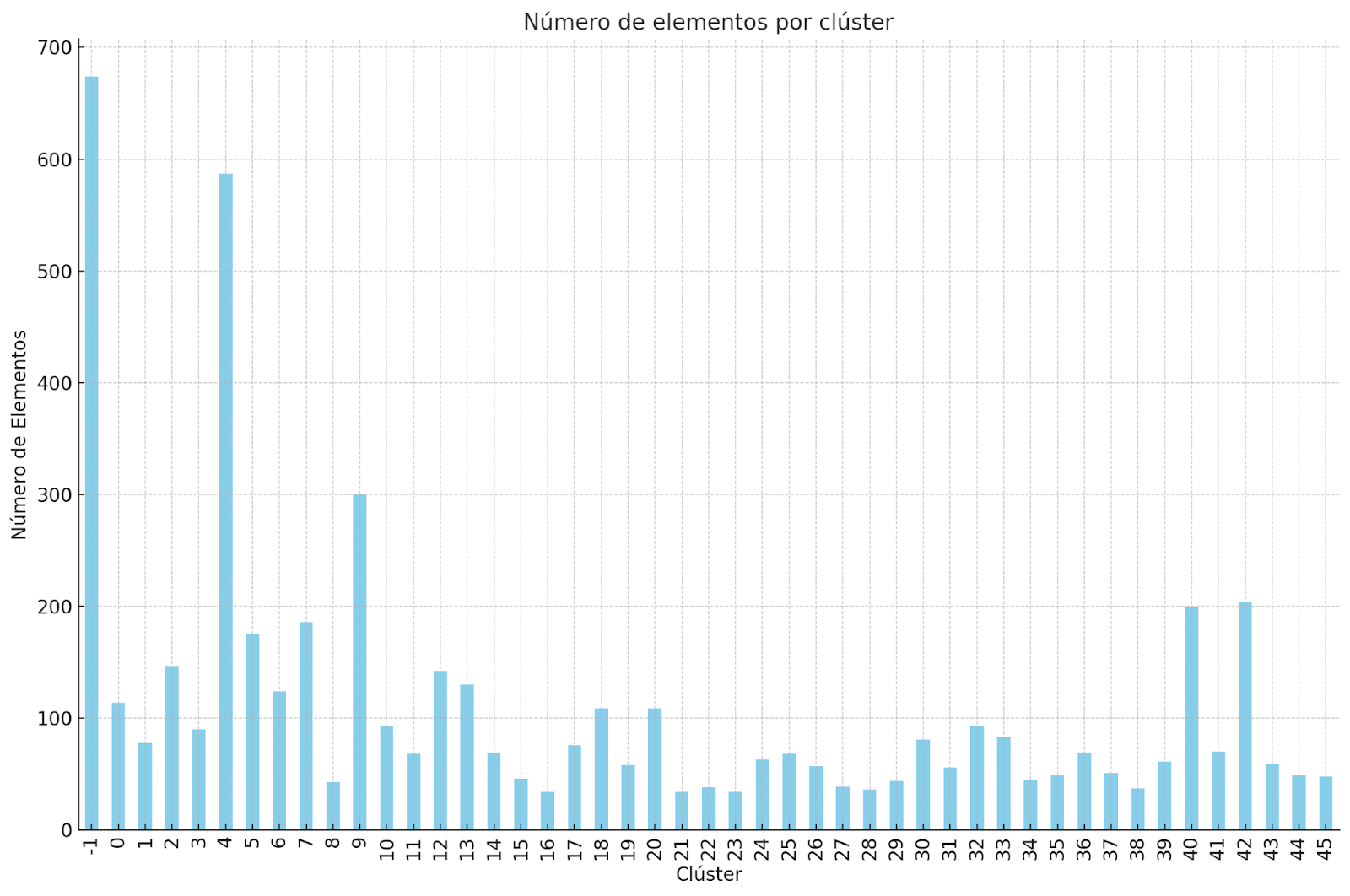
Análisis de Puntos de Ruido para Clusters Potenciales
Al revisar los resultados iniciales del clustering, observamos que algunos puntos marcados como ruido estaban cercanos entre sí, lo que sugería la posible existencia de subclusters no detectados por el algoritmo. Esto nos llevó a cuestionar si fueron clasificados correctamente como ruido.
Para investigar más a fondo, analizamos estos puntos en el gráfico. Algunos mostraron proximidad y características que indicaban un posible comportamiento de clustering. Rodeamos estos puntos con círculos en la imagen, señalando posibles áreas de subclústeres.
Al aislar estos puntos, refinamos el clustering reconsiderando posibles clasificaciones erróneas. Este proceso manual, combinado con el análisis visual, mejora la precisión del clustering y nos ayuda a identificar subclusters ocultos.
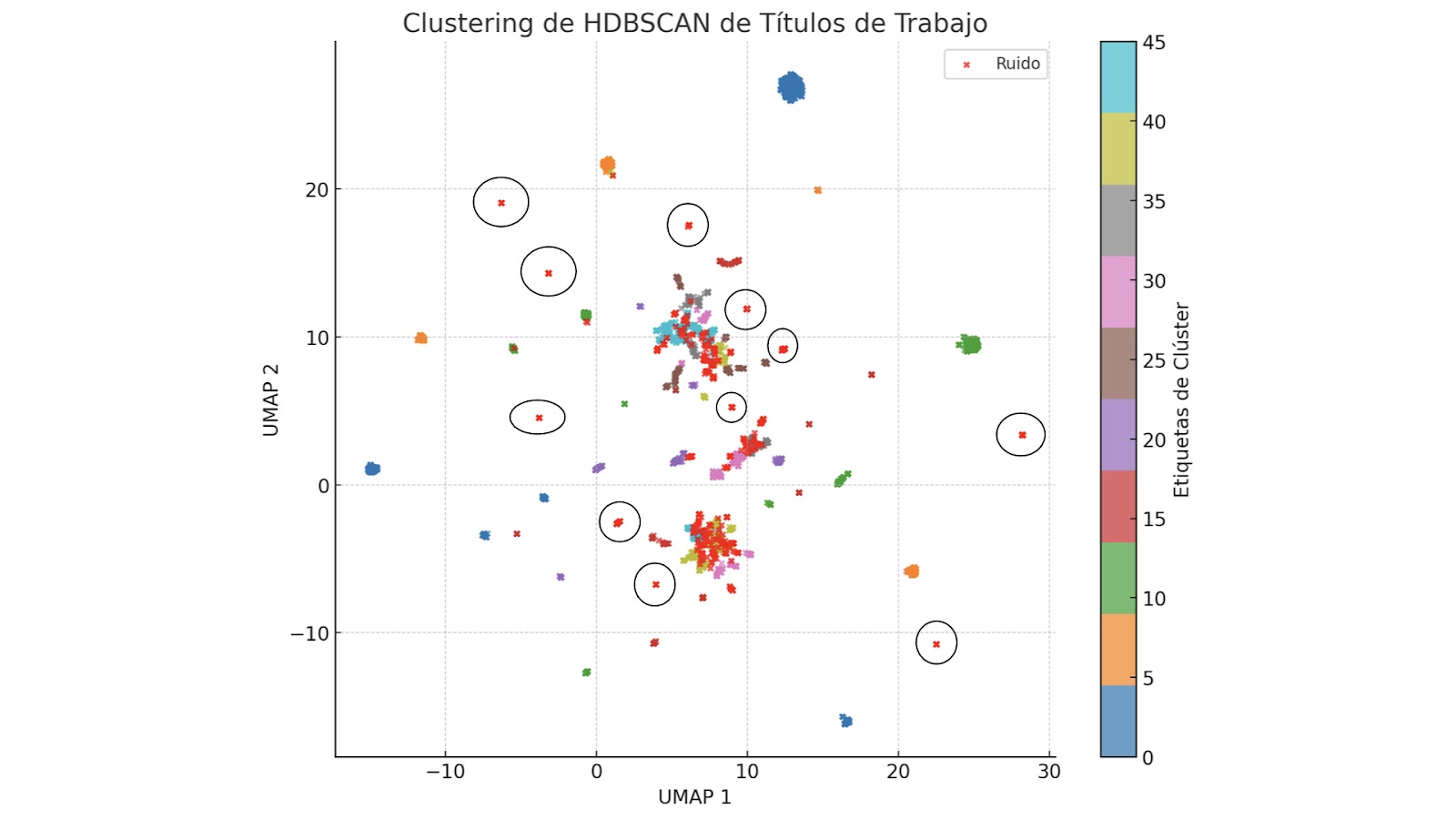
Re-Clustering de Ruido
En este paso, abordamos uno de los principales desafíos en el filtrado de bases de datos B2B: la formación de clústeres grandes y no homogéneos que dificultan la revisión manual. Una solución práctica es realizar un reclustering de algunos puntos marcados como outliers, que al graficarlos muestran potencial para formar nuevos clústeres.
¿Por qué hacer Re-Clustering?
El clustering original con HDBSCAN utiliza parámetros como min_cluster_size=30 y min_samples=10 para crear clusters prácticos y manejables. Sin embargo, estos ajustes están diseñados para trabajar con el conjunto de datos general, y priorizan evitar la creación de demasiados clusters pequeños. Al tratar con puntos de ruido que no fueron incluidos en ningún cluster inicial, es necesario reducir el umbral tanto de min_cluster_size como de min_samples para capturar subgrupos más pequeños pero significativos.
Ajustes Clave:
- Reducción de min_cluster_size y min_samples: Durante el re-clustering, redujimos el valor de min_cluster_size a 10 y min_samples a 2. Este ajuste nos permitió identificar clusters entre los puntos de ruido que eran demasiado pequeños para ser capturados durante el clustering inicial. Es importante destacar que estos parámetros solo se utilizaron en la fase de re-clustering, ya que aplicarlos desde el principio habría llevado a una proliferación de clusters diminutos, lo cual habría sido contraproducente.
Al hacer re-clustering de los puntos de ruido, reducimos efectivamente la cantidad de datos clasificados como ruido y agrupamos puntos potencialmente relevantes en nuevos clusters manejables.
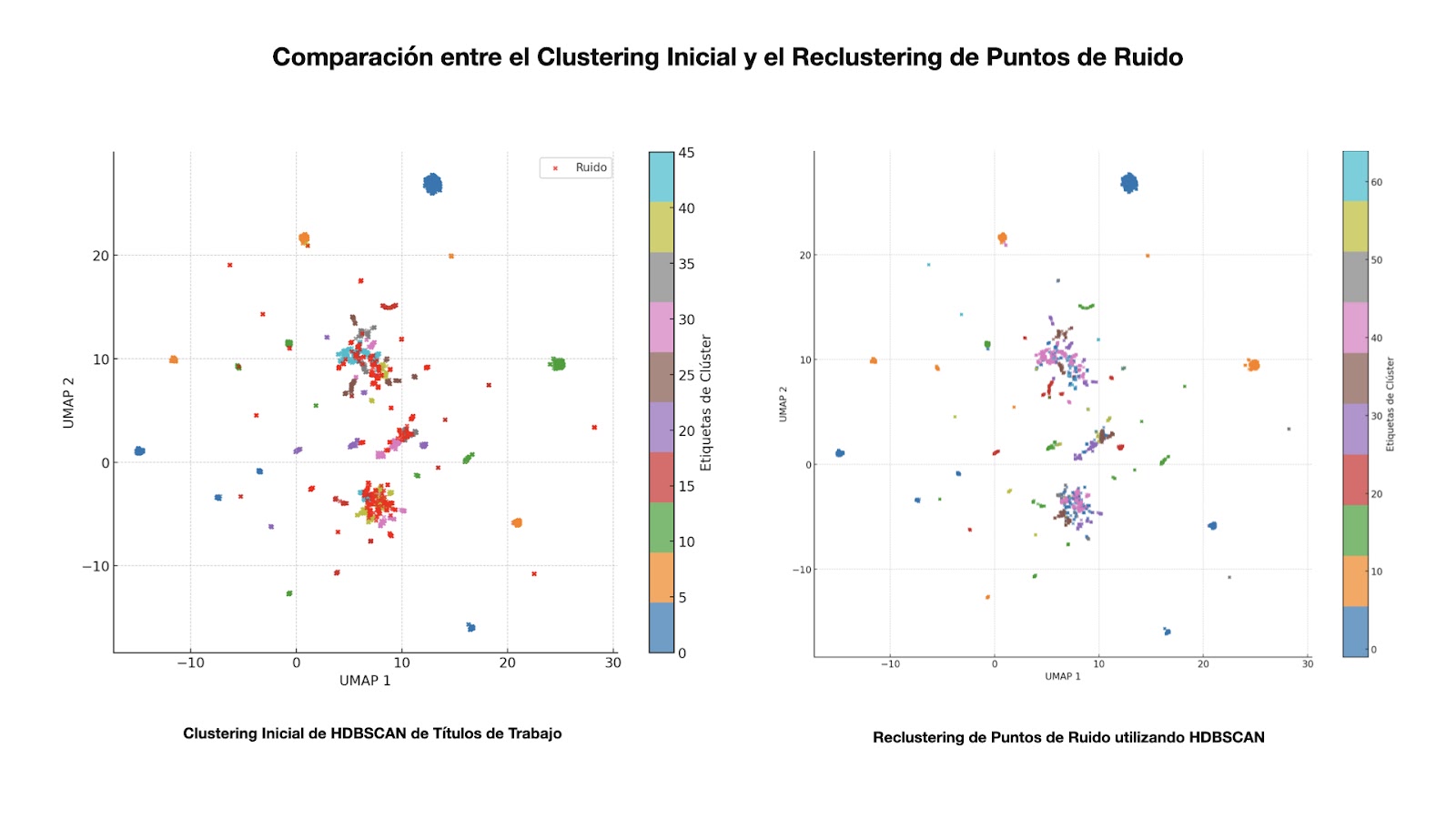
Este paso enfatiza que el clustering es un proceso iterativo, adaptable y que puede involucrar varios ajustes dependiendo del dataset específico. Al emplear esta estrategia de re-clustering, nos aseguramos de que incluso los puntos inicialmente descartados tuvieran una segunda oportunidad para agruparse de manera significativa, mejorando en última instancia la calidad de nuestros clusters y reduciendo la carga de trabajo manual en el filtrado.
Código para Re-Clustering
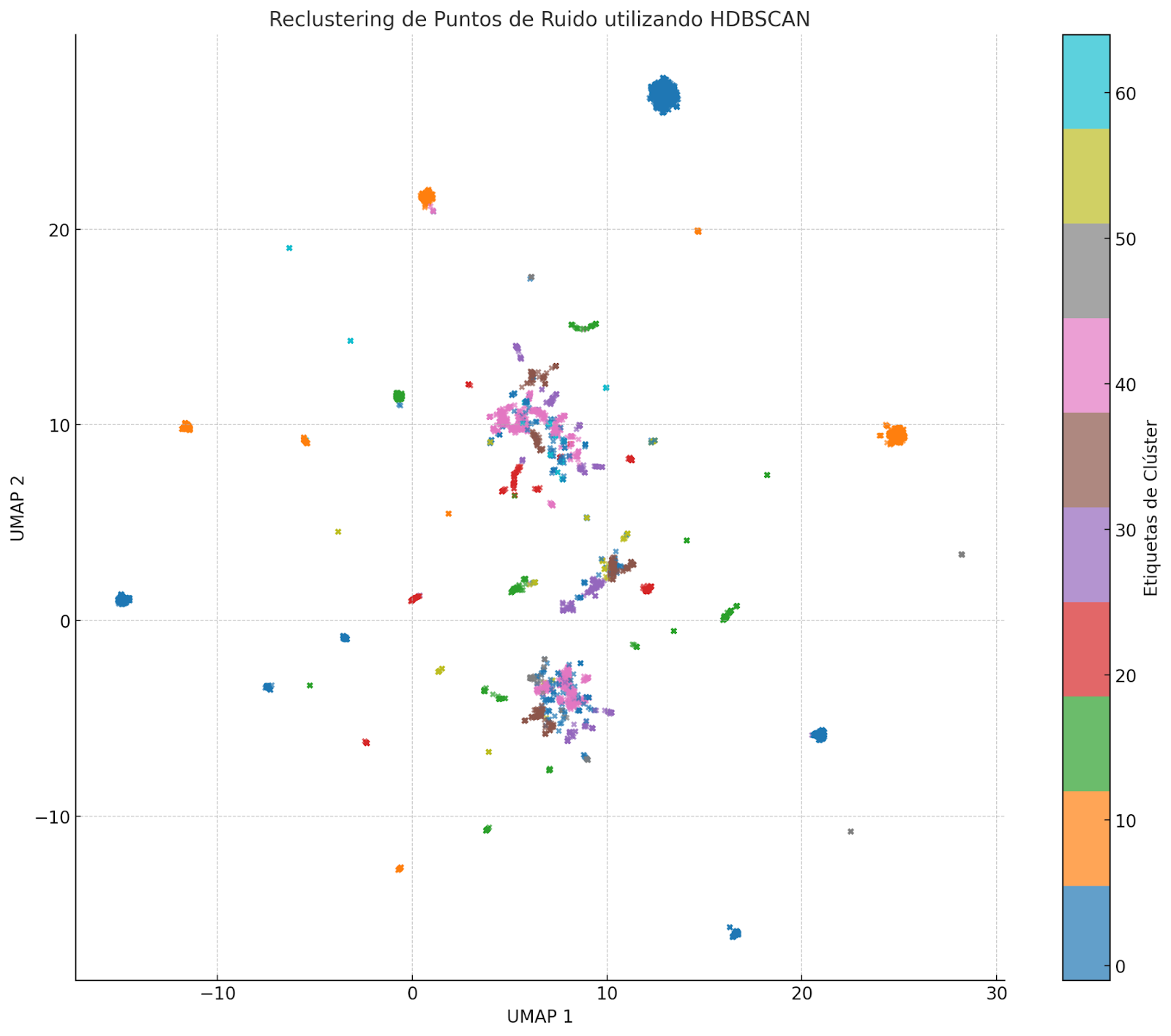
Visualización Final y Preparación para Filtrado
Después de completar el re-clustering, el siguiente paso es visualizar el conjunto final de clusters, verificar cómo se ha reducido el ruido y guardar el dataset para la revisión manual. El resultado final ahora consta de 65 clusters, con solo 281 puntos que permanecen clasificados como ruido.
Aunque el número final de clusters es 65, cada uno es consistente, lo que resulta práctico para el filtrado manual. Cuando los clusters son grandes y no homogéneos, el filtrado se vuelve tedioso, ya que tienes que revisar una variedad de títulos de trabajo que no están relacionados entre sí. En cambio, con clusters más pequeños y consistentes, puedes revisar los datos manualmente en badges de manera mucho más eficiente, lo que permite que la revisión no tome más de 30 minutos.
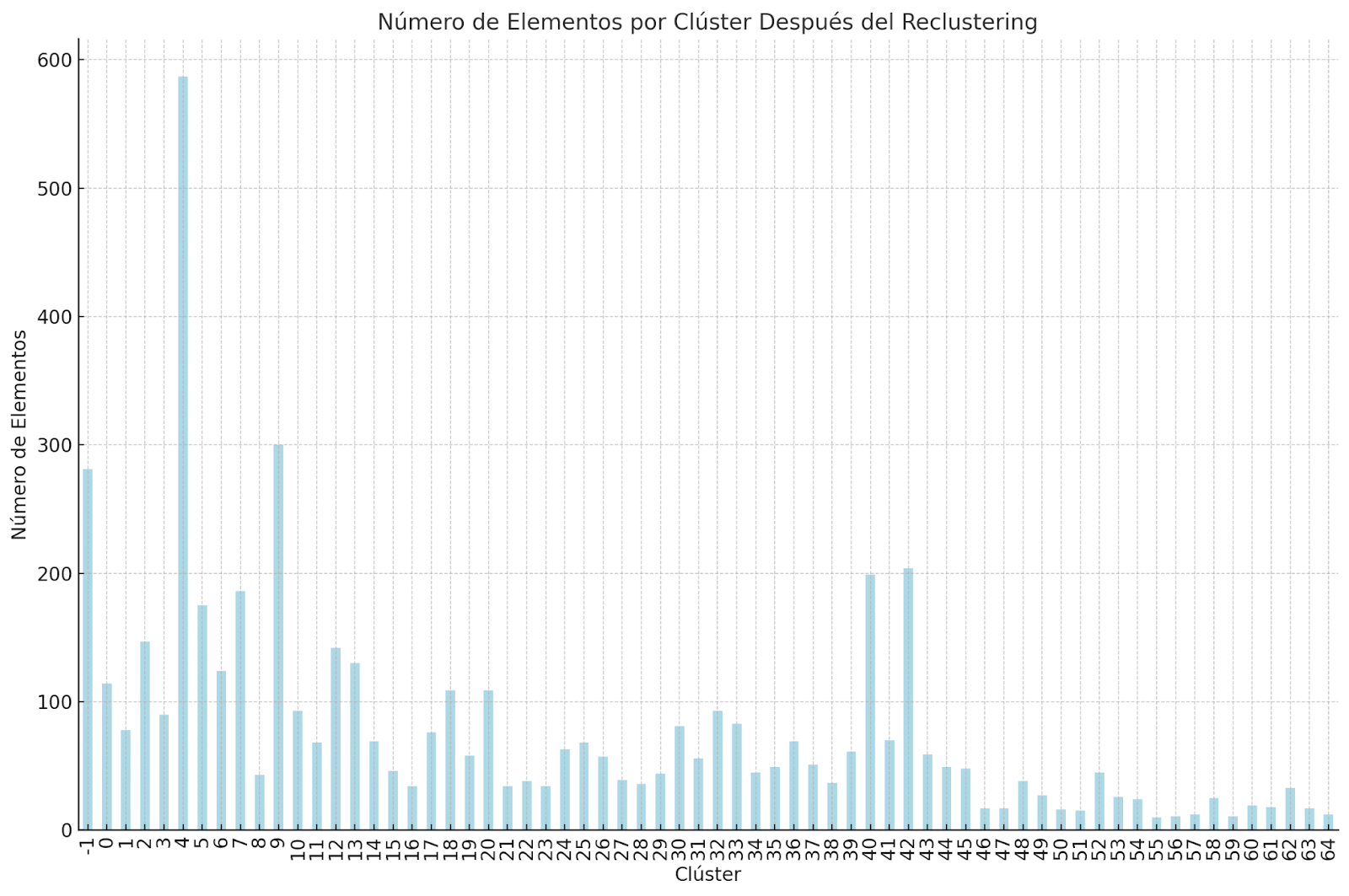
En el gráfico que generamos, puedes ver el número de elementos de los clusters finales. Una vez visualizados, el siguiente paso es simplemente guardar el dataset en un archivo CSV para el filtrado manual en Google Sheets.
The Big Picture: ¿Qué Sigue Después de HDBSCAN? Fine-Tuning de Modelos de AI
La aplicación de este método de clustering ha marcado un hito significativo en la mejora de nuestros esfuerzos de generación de leads B2B. Sin embargo, este es solo el comienzo, ya que el verdadero poder de HDBSCAN radica en lo siguiente: utilizar el filtrado manual para generar datasets donde añadimos etiquetas que clasifiquen los títulos de trabajo como correctos o incorrectos. Luego, entrenaremos a GPT con este dataset, con el objetivo de que aprenda nuestra forma de filtrar títulos de trabajo y así lograr un mayor nivel de automatización.
Nuestra experiencia ha demostrado que la combinación de clustering manual y el fine-tuning de modelos de IA es el enfoque más efectivo para manejar las complejidades de la clasificación de títulos de trabajo. No importa qué tan bueno sea tu prompt, es imposible cubrir todas las variaciones posibles dentro de los títulos que estás manejando. Si simplemente le dices a GPT que clasifique un título como "Correcto" si pertenece a un tomador de decisiones del departamento de finanzas, o "Incorrecto" si no lo es, es muy probable que el modelo cometa muchos errores.
Lo único que tienes que hacer es filtrar los datos manualmente después de usar HDBSCAN, etiquetar títulos como correctos o incorrectos, y una vez que tengas un dataset considerable, empezar el fine-tuning de un modelo de IA. Básicamente, el fine-tuning consistiría en combinar un prompt con tu dataset etiquetado. El proceso sería así:
-
Filtrar y Etiquetar Datos: Primero, aplica HDBSCAN para agrupar los títulos de trabajo en clusters. Luego, revisa manualmente estos clusters para etiquetar cada título como "correcto" o "incorrecto" basado en tus criterios específicos.
-
Preparar el Dataset: Una vez etiquetados los datos, crea un dataset que contenga ejemplos de títulos correctos e incorrectos. Este dataset será utilizado para el fine-tuning.
-
Fine-Tuning del Modelo: Utiliza este dataset para hacer fine-tuning de un modelo de IA. En este paso, combinarás el dataset etiquetado con un prompt que guiará al modelo para que entienda cómo clasificar nuevos títulos de acuerdo a tus criterios.
-
Entrenamiento y Evaluación: El modelo se entrenará con los ejemplos etiquetados para aprender las distinciones sutiles que tú has identificado. Después del entrenamiento, evalúa el modelo con datos nuevos para asegurarte que clasifica los títulos correctamente según tus necesidades.
-
Implementación y Ajustes: Finalmente, implementa el modelo en tu workflow y realiza ajustes adicionales según sea necesario para mejorar su precisión.
Conclusión: Construyendo un Futuro Inteligente, Escalable y Basado en Datos para la Generación de Leads B2B
La transición de métodos tradicionales de filtrado de datos a técnicas avanzadas como HDBSCAN y el fine-tuning de modelos de IA ha transformado nuestra manera de clasificar títulos de trabajo. Este cambio ha sido clave para mejorar la precisión en el proceso de generación de leads B2B.
HDBSCAN ha facilitado la identificación de prospectos relevantes al filtrar el ruido y agrupar títulos de manera más efectiva. Sin embargo, esto es solo el comienzo. Los datos generados a través del clustering manual y la revisión no solo ayudan en el análisis inmediato, sino que también sientan las bases para una mayor automatización en el futuro.
En Z&S Consulting, nos apasiona aplicar la ciencia de datos para abordar los desafíos complejos en la generación de leads B2B y así poder obtener resultados excepcionales en campañas de Cold Email.
